The AkuAuction smart contract had several core defect, including not handling multiple bids and open itself up to a DoS attack. Here is an easy to understand breakdown.
Introduction
Micah Johnson’s Akutar’s drop has been well talked about in the NFT scene recently due to defects in the auction smart contract. This post is an effort to explain what happened (in non-technical language) and to offer ways to prevent similar issues in future contracts.
There is no negativity or judgement in this post. I believe we are still early in building NFT contracts and communities. We need to learn form each other, support each other, and continue to evolve in order to create a positive, generous community.
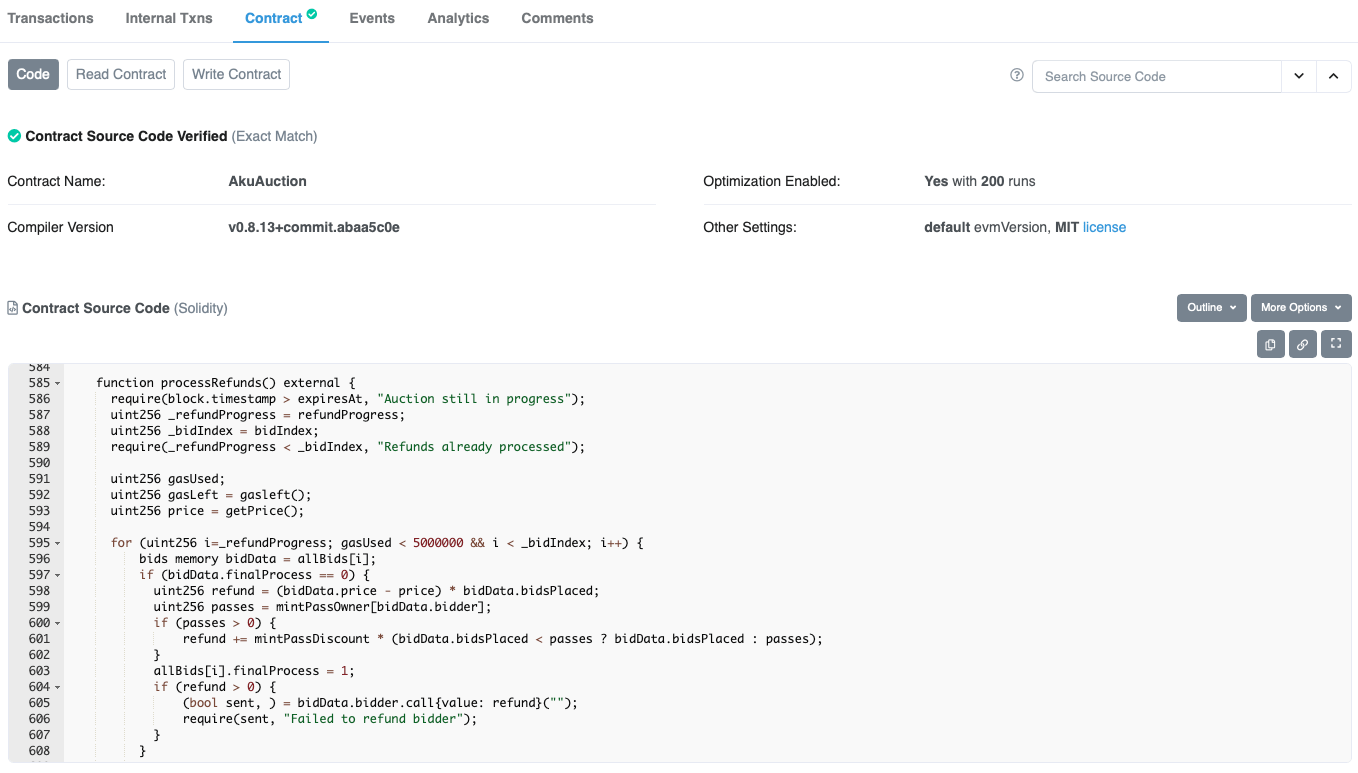
Here is the AkuAuction smart contract, for your reference. Don’t worry if you can’t understand it as I will explain the relevant parts:
https://etherscan.io/address/0xf42c318dbfbaab0eee040279c6a2588fa01a961d#code
What happened
There are two primary defects in the Smart Contract, resulting in two separate incidents:
- Dutch Auction refunds were temporarily frozen.
- Proceeds from the sale are forever locked in the contract.
Defect 1: Frozen Refunds
There was an exploit in the logic of the “processRefunds” function that allowed an attacker to halt the refund process. This can be considered a Denial of Service (DoS) vulnerability. Just like how a website can become unavailable because of too much traffic, the AkuAuction contract’s refund function was rendered unavailable by an external smart contract.
To understand the vulnerability, let’s look at how the AkuAuction contract refund logic works. There are 4 main steps:
- Get each bidder sequentially
- Refund them some ETH
- Check to make sure the refund was successful
- Get the next bidder in the sequence and repeat
The vulnerability here lies in step 3. To explain, we can discuss briefly the two types of participants on the Ethereum network:
- A user with a wallet (referred to as an “Externally Owned Account” or EOA)
- A smart contract
If a bidder sent funds from a regular wallet (e.g MetaMask) then the refund is simply sent back to their wallet in a regular old wallet-to-wallet transaction. No problem.
However, if a bidder sent funds from a smart contract, they can modify how the refund is handled on their side. Smart contracts can act like EOAs, but they offer developers the opportunity to change how “payable” transactions work (payable meaning any transaction that can accept ETH). The attacker wrote a smart contract that would cause any ETH sent to it to return a failure message. The AkuAuction refund logic captured that failure and would try to re-send the ETH. And it would fail again, and again. Rinse and Repeat.
Since the refund logic gets bidders sequentially in the order they bid, there was no way to skip this malicious bidder. The result was that anyone who bid after them could not receive their refund since the refund function could not proceed. Thankfully the attacker built in a switch to allow their contract to eventually receive funds, which then unlocked the refunds for all the other bidders.
Proposed Solutions
So how could this have been prevented?
Option 1: Deny Smart Contract Bids
The blunt force approach would have been to deny smart contracts from placing a bid. It is a simple check in Solidity and could have been added last minute. However, it is a really a poor approach as it prevents multi-sig wallets or more advanced security wallets from bidding. Ideally the contract is secure no matter who calls it.. but in a pinch, it would have worked.
Option 2: Ignore Refund Failures
The naive way to do this is to just send the refund and don’t care if it succeeded. That would require the least amount of code changes. A more robust approach would be to flag the refund as “Failed” on the bidder and then handle it manually later. This would require a few small code changes, but nothing drastic.
As a note: There are some ways a bidder could try and grief AkuAuction using smart contracts, with this approach, but as far as I’m aware it would just result in burning gas from the AkuAuction contract and would still allow for the refunds to process.
Option 3: Require bidders to claim their refund
This is a simpler to implement than what was built and could cut down both on gas and extra code. Ultimately deferring the refund to the bidder removes a lot of the liability and security issues involved in “pushing” ETH to users. The general rule of thumb for payments is “pull, not push”. This function would check to see if the wallet had placed any bids and still needed to be refunded. If so, send them the ETH. If not, do nothing.
One caveat is the the bidders would have to pay a small amount of gas for their refund. One could include a small gas-stipend in the refund as a make good.
This option would require a lot of code changes to the contract, but would also simplify everything in the process. This would be my recommend approach as it removes the need for the contract push funds to thousands of other EOAs or contracts.
Defect 2: Locked Proceeds
This one is sucks and is gut-wrenching. Please understand that it is so much easier for me to analyze (and for people to criticize) this stuff after the fact. Having a defect that allows funds to be locked up is a LOT of emotional and mental anguish on the team to bear. Remember that before you go FUDing.
The explanation of what went wrong here is simple: The Auction contract did not properly account for multiple bids by the same bidder.
There are two primary counters in the contract: “Total Bids” and “Refunds Issued” (referred to as “refundProgress” in the contract).
To make a bid, the “bid” function is called with the amount of bids to make. After some validation, the “Total Bids” counter increments by the “amount” of bids being made. So if there were 10 existing bids and I placed 2 more, the count would increase to 12.
In order to call the “claimProjectFunds” function, the smart contract requires that the Dutch Auction refunds be issued. It does this by checking to make sure that the “Refunds Issued” counter is greater than or equal to the “Total Bids” counter. The project funds then can not be claimed if there are less refunds than bids. The intent here is to prove to the public that the Akutars team could not withdraw until the auction finished and all refunds were processed — which is a great intent!
The defect here is in how the “processRefunds” function was written: when refunding a bidder with multiple bids, it increments the “Refunds Issued” by one, regardless of how many bids the bidder made. So if I made 2 bids like above, and there were 10 refunds already issued, the “Refunds Issued” counter would only increment to 11, but the “Total Bids” counter is 12.
Thus every call to “claimProjectFunds” fails because “Refunds Issued” is less than “Total Bids”. For those curious, the smart contract has “Total Bids” set to 5,495 and “Refunds Issued” set to 3,669, meaning that 1,826 bidders submitted more than one bid.
Solutions
So how could this have been prevented?
Option 1: Better testing
Sadly this is the easiest answer. There are several different counters used in the code, all used slightly different. Having proper tests written to ensure that multiple bids could be accepted, refunded, and then withdrawn would have caught this. Once caught, it would have only required a small change to a single line of code.
Option 2: Use State Management
The current implementation ensures that all refunds + gas are removed from the smart contract’s ETH balance before allowing the project owner to claim. This makes senses for accountability reasons, but also makes the logic for calculating for the claim complicated. If you were to use a “state” that indicated when the refunds were finished, then there would be no need to compare the different counters.
A naive implementation of this would be to set “refundsIssued = true” once the existing “processRefunds” function saw that there were no more refunds to process. Then in “claimProjectFunds” require that “refundsIssued” is true before allowing the claim. This removes all need for counter comparison in the claim function.
A more robust, but nuanced solution would be start a “Refund Claim” period were bidders would “pull” their refunds.. say 48 hours. After that, the project owners would be allowed to claim their funds. The project owners could then manually refund any wallet who didn’t claim their refund during this period, or could leave a refund buffer in the Auction contract.
Option 3: Emergency Withdraw
There is an existing function for bidders, so implementing this for the project owner could also work. The best way would be to time lock it.. say 3 days after the refunds were issued, allow the project owner to withdraw funds no matter what. OR if the community really trusted you, don’t put any restrictions on it at all!
Ethereum offers all smart contracts the ability to “self destruct” and send all contract funds to an address. Unfortunately this method is private by default, so if you wanted to expose it to the contract owner, it would need to be added to the contract in advance.
Wrap Up
Building smart contracts is hard — you generally only have one shot. As a dev, one really needs to embrace community code reviews and audits, and do so without ego. As a collector, it can be extremely difficult to understand what is actually happening when something goes wrong.
Hopefully this post has helped explain -in not too much technical detail- what happened with this auction, and how future drops can learn from it.